The together Argument
By default, JAVELIN will fit each line to the continuum separately. However, in some cases, analysis requires that each line be fit to the continuum together, with the same model. JAVELIN uses this setting by default, which has been implemented in pyPetal with the together argument for the JAVELIN module.
If together=True, JAVELIN will fit all light curves to the same model. In this case, there will be a directory labeled javelin in output_dir, containing all of the diagnostic files and figures.
If together=False, each line will be fit to the continuum separately. In this case, there will be a directory labeled javelin in the subdirectory for each line. This directory will then contain all of the diagnostic files and figures for that line.
We’ve already seen together=False in the basic example, so now we’ll set together=True:
[1]:
%matplotlib inline
import pypetal_jav.pipeline as pl
output_dir = 'javelin_output2/'
line_names = ['Continuum', 'H-alpha', 'H-beta']
params = {
'nwalker': 50,
'nburn': 50,
'nchain': 100,
'together': True
}
res = pl.run_pipeline( output_dir, line_names,
javelin_params=params,
verbose=True,
plot=True,
file_fmt='ascii')
Running JAVELIN
--------------------
rm_type: spec
lagtobaseline: 0.3
laglimit: [[-1976.98849, 1976.98849], [-1976.98849, 1976.98849]]
fixed: False
p_fix: False
subtract_mean: True
nwalker: 50
nburn: 50
nchain: 100
output_chains: True
output_burn: True
output_logp: True
nbin: 50
metric: med
together: True
--------------------
start burn-in
nburn: 50 nwalkers: 50 --> number of burn-in iterations: 2500
burn-in finished
save burn-in chains to /home/stone28/pypetal/javelin_output2/javelin/burn_cont.txt
start sampling
sampling finished
acceptance fractions for all walkers are
0.69 0.67 0.78 0.76 0.74 0.78 0.66 0.71 0.67 0.72 0.68 0.71 0.70 0.74 0.77 0.70 0.75 0.73 0.74 0.67 0.73 0.77 0.63 0.80 0.70 0.60 0.75 0.68 0.70 0.63 0.75 0.62 0.75 0.72 0.75 0.77 0.74 0.70 0.67 0.67 0.79 0.78 0.68 0.81 0.69 0.56 0.70 0.69 0.81 0.79
save MCMC chains to /home/stone28/pypetal/javelin_output2/javelin/chain_cont.txt
save logp of MCMC chains to /home/stone28/pypetal/javelin_output2/javelin/logp_cont.txt
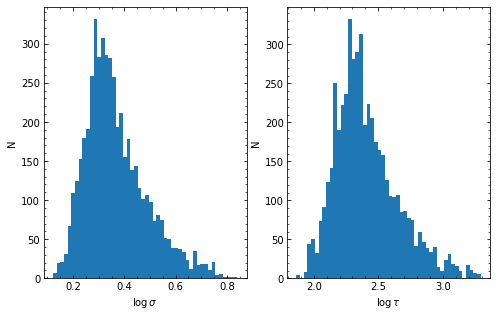
HPD of sigma
low: 1.810 med 2.209 hig 3.077
HPD of tau
low: 151.064 med 230.571 hig 449.423
run single chain without subdividing matrix
start burn-in
using priors on sigma and tau from continuum fitting
[[ 1.81 151.064]
[ 2.209 230.571]
[ 3.077 449.423]]
penalize lags longer than 0.30 of the baseline
nburn: 50 nwalkers: 50 --> number of burn-in iterations: 2500
burn-in finished
save burn-in chains to /home/stone28/pypetal/javelin_output2/javelin/burn_rmap.txt
start sampling
sampling finished
acceptance fractions are
0.01 0.00 0.01 0.02 0.06 0.03 0.03 0.04 0.03 0.03 0.02 0.02 0.04 0.05 0.02 0.00 0.03 0.03 0.00 0.00 0.04 0.01 0.01 0.03 0.03 0.02 0.01 0.04 0.01 0.05 0.04 0.03 0.01 0.06 0.03 0.05 0.01 0.01 0.04 0.00 0.04 0.05 0.01 0.08 0.04 0.03 0.00 0.03 0.02 0.02
save MCMC chains to /home/stone28/pypetal/javelin_output2/javelin/chain_rmap.txt
save logp of MCMC chains to /home/stone28/pypetal/javelin_output2/javelin/logp_rmap.txt
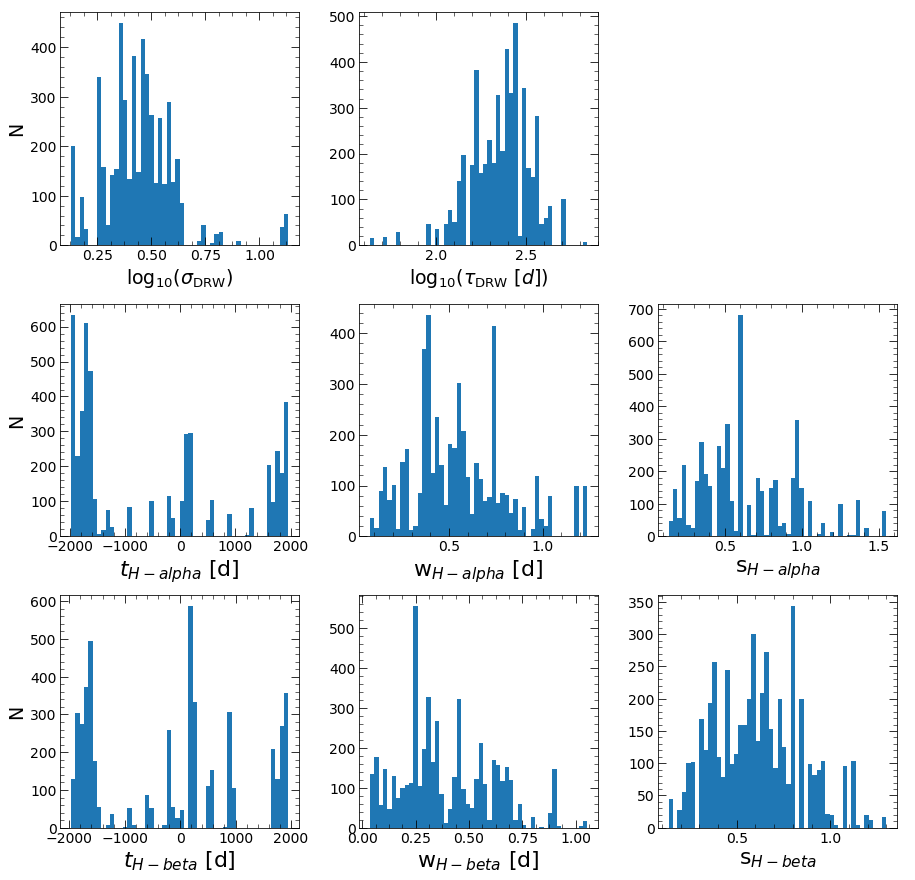
HPD of sigma
low: 1.933 med 2.775 hig 3.801
HPD of tau
low: 157.482 med 242.727 hig 320.592
HPD of lag_H-alpha
low: -1853.951 med -1275.708 hig 1724.027
HPD of wid_H-alpha
low: 0.313 med 0.520 hig 0.785
HPD of scale_H-alpha
low: 0.347 med 0.597 hig 0.962
HPD of lag_H-beta
low: -1729.672 med 177.567 hig 1686.832
HPD of wid_H-beta
low: 0.189 med 0.346 hig 0.642
HPD of scale_H-beta
low: 0.367 med 0.592 hig 0.854
covariance matrix calculated
covariance matrix decomposed and updated by U
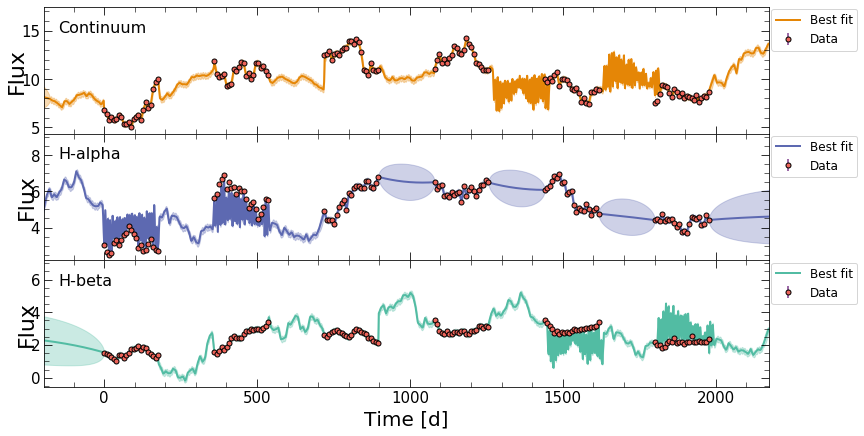
In this case, the output will have only one dict, containing the group fit:
[2]:
res
[2]:
{'bestfit_model': <javelin.zylc.LightCurve at 0x7f85aac220d0>,
'cont_dat': <javelin.zylc.LightCurve at 0x7f860c072490>,
'cont_hpd': array([[0.593, 5.018],
[0.792, 5.441],
[1.124, 6.108]]),
'cont_model': <javelin.lcmodel.Cont_Model at 0x7f860c06cb10>,
'hpd': array([[ 6.589e-01, 5.059e+00, -1.854e+03, 3.125e-01, 3.472e-01,
-1.730e+03, 1.895e-01, 3.668e-01],
[ 1.021e+00, 5.492e+00, -1.276e+03, 5.203e-01, 5.971e-01,
1.776e+02, 3.463e-01, 5.917e-01],
[ 1.335e+00, 5.770e+00, 1.724e+03, 7.848e-01, 9.621e-01,
1.687e+03, 6.422e-01, 8.538e-01]]),
'rmap_model': <javelin.lcmodel.Rmap_Model at 0x7f85cc3358d0>,
'sigma': array([2.204, 2.204, 2.204, ..., 3.119, 3.119, 3.119]),
'tau': array([226.996, 226.996, 226.996, ..., 185.37 , 185.37 , 185.37 ]),
'tophat_params': array([[ 1.578e+02, 1.578e+02, 1.578e+02, ..., -1.854e+03, -1.854e+03,
-1.854e+03],
[ 5.131e-01, 5.131e-01, 5.131e-01, ..., 4.013e-01, 4.013e-01,
4.013e-01],
[ 1.043e+00, 1.043e+00, 1.043e+00, ..., 6.571e-01, 6.571e-01,
6.571e-01],
[ 2.279e+02, 2.279e+02, 2.279e+02, ..., -1.805e+02, -1.805e+02,
-1.805e+02],
[ 5.477e-01, 5.477e-01, 5.477e-01, ..., 3.074e-01, 3.074e-01,
3.074e-01],
[ 6.136e-01, 6.136e-01, 6.136e-01, ..., 9.130e-01, 9.130e-01,
9.130e-01]]),
'tot_dat': <javelin.zylc.LightCurve at 0x7f85ec17ae50>}
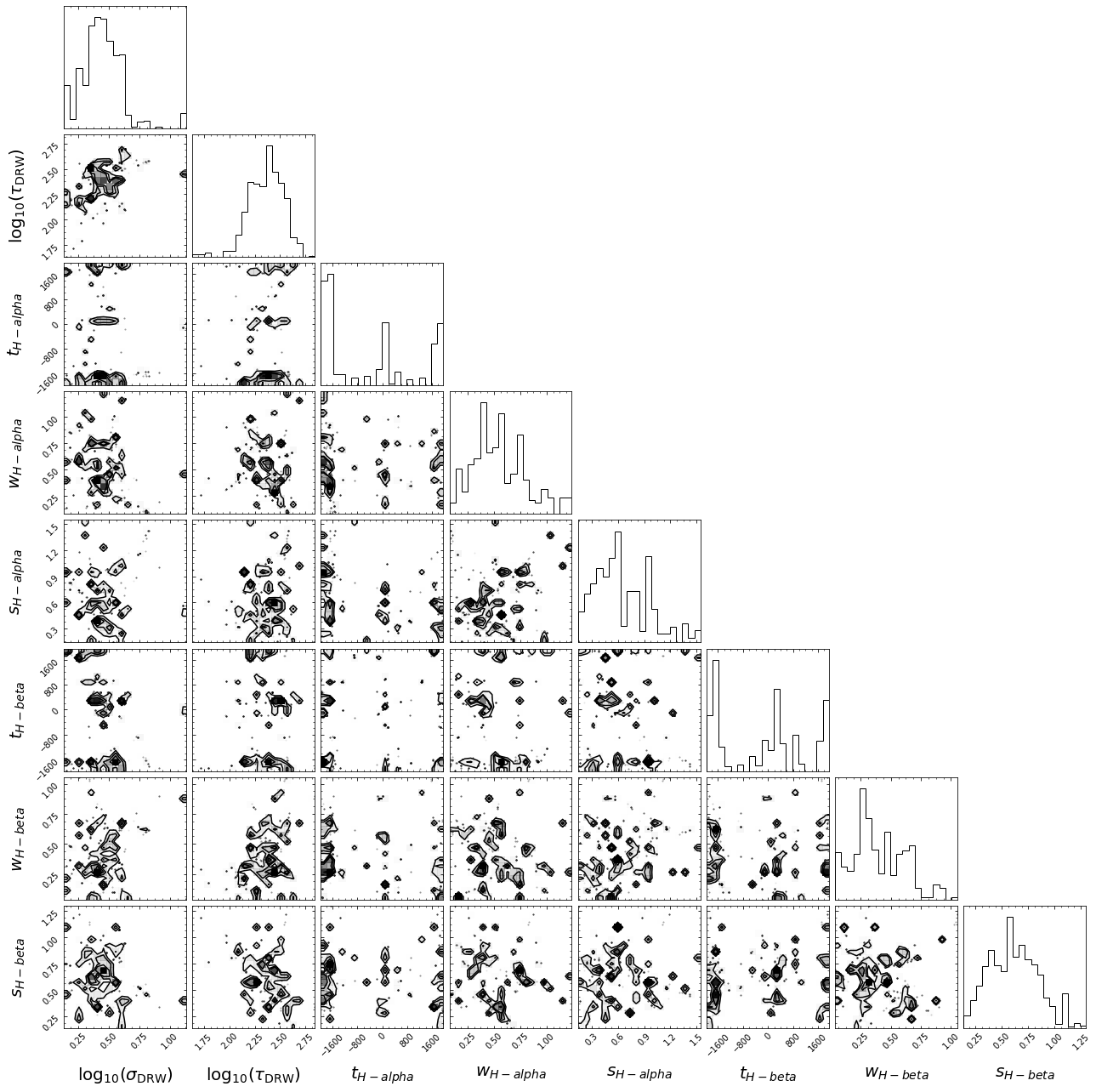
However, the tophat_params key will now be of length \(2 + 3 \cdot ({\rm number \ of \ lines})\) in the order: \([ \log(\sigma_{\rm DRW}), \log(\tau_{\rm DRW}), t_{\rm line1}, w_{\rm line1}, s_{\rm line1}, t_{line2}, ... ]\)
The output directory will be:
javelin_output2/
├── Continuum/
├── H-alpha/
├── H-beta/
├── javelin/
│ ├── burn_cont.txt
│ ├── burn_rmap.txt
│ ├── logp_cont.txt
│ ├── logp_rmap.txt
│ ├── chain_cont.txt
│ ├── chain_rmap.txt
│ ├── Continuum_lc_fits.dat
│ ├── H-alpha_lc_fits.dat
│ ├── H-beta_lc_fits.dat
│ ├── cont_lcfile.dat
│ ├── H-alpha_lcfile.dat
│ ├── H-beta_lcfile.dat
│ ├── javelin_histogram.pdf
│ ├── javelin_corner.pdf
│ └── javelin_bestfit.pdf
├── processed_lcs/
├── pyroa/
├── pyroa_lcs/
└── light_curves